From Pattern to Information – oder wie aus Texten Bilder werden
Am Institut für grafische Wissensorganisation, einem Start-up der Universität Rostock, hat Stefan Pforte vor ein paar Jahren ein Verfahren entwickelt, mit dem sich Texte auswerten und in interpretierbare Bilder umwandeln lassen.
„Textrapic“ – text transform to picture – heißt dieser technische Weg der Textanalyse. Die Teilnehmer des Innovationsforums „FroPatI – From Pattern to Information“, dass Ende November in Rostock stattfand, waren nun auf der Suche nach wirtschaftlich tragfähigen Anwendungsfeldern von „Textrapic“. Eine Zukunft der Software könnte im Bereich des Journalismus liegen, wo es häufig darum geht, Fakten aus einer Flut von Texten herauszufiltern.
Entscheidend für seine Idee, ein Programm wie „Textrapic“ zu entwickeln, war für den Pädagogen Stefan Pforte die Lektüre des Buchs „Geist im Netz“ von Manfred Spitzer. Spitzer beschreibt darin, wie das menschliche Gehirn funktioniert, wie die Nervenzellen Denken, Lernen, Fühlen und Handeln hervorbringen. Seitdem denkt Pforte darüber nach, wie sich Vorgänge, die im Gehirn ablaufen, künstlich erzeugen lassen.
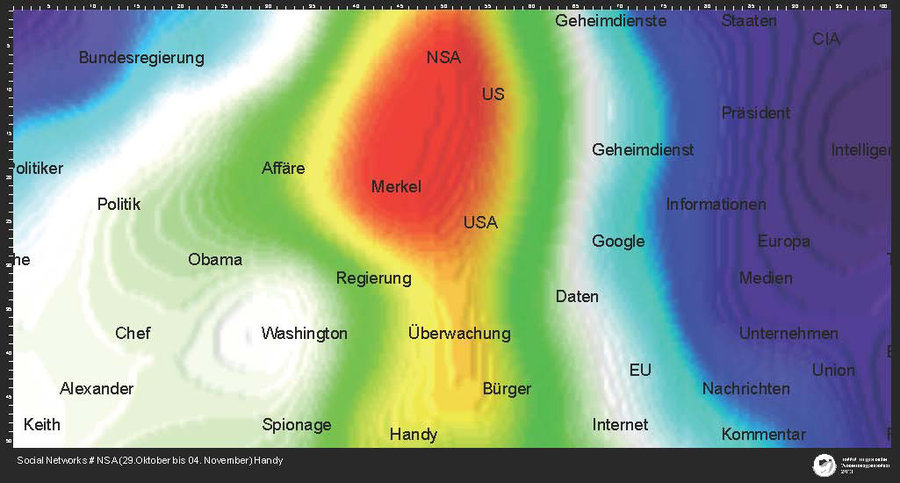
Mit dem Text-Mining-Algorithmus „Textrapic“ ist ihm ein Schritt in diese Richtung gelungen. Das Programm durchsucht Texte nach individuell bestimmbaren Begriffen und stellt dabei fest, wie häufig diese Begriffe vorkommen. Diese Häufigkeiten werden dann in so genannte Vektoren umgewandelt, aus denen ein neuronales Netz entsteht. Das Ergebnis der Textanalyse ist damit ein buntes Bild, das an eine Landkarte oder Wärmebildaufnahme erinnert. Unterschiedliche Farbintensitäten sind Indikator für die Häufigkeit der im Text vorkommenden Begriffe.
Was kann diese Software?
Dadurch, dass mehrere Begriffe abgefragt werden, können Texte und Stellen in Texten gefunden werden, in denen diese Begriffe gemeinsam gehäuft auftauchen. Auf diese Art und Weise können sinntragende Stellen im Text herausgearbeitet werden.
Der Nutzer von „Textrapic“ kann mit diesem Verfahren also in verkürzter Recherchezeit erfahren, welche Texte relevant sind und welche relevanten Informationen in einem umfangreichen Text wo stehen. Pforte geht deshalb davon aus, dass „der Bereich Journalismus die interessanteste Weiterentwicklungsperspektive bietet“.
Ein Beispiel: Für die Zeit vom 29. Oktober bis 04. November sollen Facebook- und Twitter-Nachrichten analysiert werden. Ziel ist es herauszufinden, was die dominierenden Themen in diesen beiden Social-Media-Kanälen waren. Das Material besteht aus rund 850.000 Nachrichten. Die Analyse mit „Textrapic“ zeigt, dass der Begriff „NSA“ extrem häufig vorkam und in dem Zusammenhang auch „Merkel“, „Obama“ und „Überwachung“. Anschließend kann der Frage nachgegangen werden, welche Nachrichten hinter der Häufigkeit dieser Begriffe stehen oder warum darüber geschrieben wurde. Hierzu kann der Nutzer in die Texte zurückgehen und die Stellen herausgreifen, in denen die Begriffe gehäuft auftreten. Die Software hilft dem Anwender also, ohne zeitintensives Lesen herauszufinden, welche Themen diskutiert wurden, welche Aussagen gemacht wurden oder ob der Text für die Recherche von Bedeutung ist.
Deutlich wurde auf dem Innovationsforum, dass eine Weiterentwicklung von „Textrapic“ nur gemeinsam mit den (potenziellen) Anwendern möglich ist. Erste Ansätze, wie dies realisiert werden kann, konnten erarbeitet werden. Bisher ist das Institut für grafische Wissensorganisation der Uni Rostock als Dienstleister gefragt. Stefan Pforte aber will mit „Textrapic“ mehr „als nur Erkenntnis“.